三、“股票数据定向爬虫”实例 1、“股票数据定向爬虫”实例介绍 (1)功能描述 (2)候选数据网站的选择 (3)程序的结构设计 2、“股票数据定向爬虫”实例编写 3、“股票数据定向爬虫”实例优化 (1)速度提高:...
”学习 学习笔记 实战 数据 爬虫 网络爬虫 股票“ 的搜索结果
目录 一、Re(正则表达式)库入门 1、正则表达式的概念 (1)正则表达式的定义 (2)正则表达式的概念 (3)正则表达式的举例 (4)正则表达式的特点 (5)正则表达式在文本处理中十分常用 (6)正则表达式的使用 ...
学习笔记:在学习过程中,我们整理了丰富的学习笔记,这些笔记包含了重点知识点的总结、实战经验分享以及常见问题的解答。通过阅读这些笔记,你可以随时巩固所学,解决学习中遇到的问题,提高学习效率。 项目实战:...
selenium+firefox在定位时遇到selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: 由于是js加载页面,想确认是否是js的原因,随后进行多次调试时发现“//div”竟然也出现了...
股票数据定向爬虫1、股票数据定向爬虫”实例介绍(1)功能描述:(2)理解网站的选取过程(3) 程序的结构设计2、股票数据定向爬虫”实例编写 1、股票数据定向爬虫”实例介绍 (1)功能描述: 目标:获取上交所和...
记录python爬虫学习全程笔记、参考资料和常见错误,约40个爬取实例与思路解析,涵盖urllib、requests、bs4、jsonpath、re、 pytesseract、PIL等常用库的使用。 爬虫(Web Crawler)是一种自动化程序,用于从互联网...
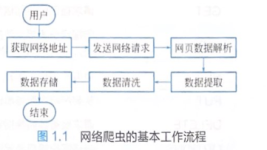
爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL...
python爬虫学习笔记(一)——初识爬虫 python爬虫学习笔记(二)——解析内容 开始实战爬取豆瓣TOP250电影 首先还是重新复习下爬虫的基本流程: 发起请求 获取响应内容 解析内容 保存数据 1. 发起请求 首先观察豆瓣...
内容概要: 本文首先以模拟登录为例,讲解了使用Session对象保持登录状态的方法,给出了示例代码。然后介绍了爬取API数据的思路,并提供了解析JSON的代码...总体来说,本文实战性强,非常适合作为Python爬虫学习的参考资料。
python3网络爬虫笔记与实战源码。记录python爬虫学习全程笔记、参考资料和常见错误,约40个爬取实例与思路解
2、通过chrome开发工具,触发请求,并获取数据 3、用到selenium库 思路如下: 1、用selenium模拟浏览器操作,获得ul/li下面的data 2、用beautiful soup4解析缓存下来的data 3、加载pandas库,将data导出至csv文件 ...
Python爬虫是一种使用Python编程语言开发的自动化网页抓取工具。它们主要用于从互联网上获取数据,通常用于收集公开信息,如新闻文章、社交媒体帖子、价格信息等。
人类社会已经进入大数据时代,大数据深刻改变着我们的工作和生活。随着互联网、移动互联网、社交网络等的迅猛发展,各种数量庞大、种类繁多、随时随地产生和更新的大数据,蕴含着前所未有的社会价值和商业价值。
视频教程的老师很棒,学到很多,偏实战,很适合有编程基础的同学学习
自学Python爬虫路上的实战笔记,由浅到深逐步深入学习Python 爬虫
(狂神)ElasticSearch快速入门笔记,ElasticSearch基本操作以及爬虫(Java-ES仿京东实战),包含了小狂神讲的东西,特别适合新手学习,笔记保存下来可以多看看。好记性不如烂笔头哦~,ElasticSearch,简称es,es是一个...
崔庆才著《Python3 网络爬虫开发实战》学习笔记之1.1:HTTP基本原理
学习笔记:在学习过程中,我们整理了丰富的学习笔记,这些笔记包含了重点知识点的总结、实战经验分享以及常见问题的解答。通过阅读这些笔记,你可以随时巩固所学,解决学习中遇到的问题,提高学习效率。 项目实战:...
Python 网络爬虫笔记8 – 股票数据定向爬虫 Python 网络爬虫系列笔记是笔者在学习嵩天老师的《Python网络爬虫与信息提取》课程及笔者实践网络爬虫的笔记。 课程链接:Python网络爬虫与信息提取 参考文档: ...
淘宝商品比价定向爬虫1、“淘宝商品比价定向爬虫”实例介绍(1)功能描述(2)定向爬虫可行性(3)程序的结构设计2、“淘宝商品比价定向爬虫”实例编写3、小结 1、“淘宝商品比价定向爬虫”实例介绍 ...
和Requests库网络爬取实战网络爬虫的“盗亦有道”网络爬虫的限制Robots协议Robots协议的遵守方式Robots协议的使用Requests库网络爬取实战实例1:京东商品页面的爬取实例2:亚马逊商品页面的爬取实例3:百度/360搜索...
今天博主在学习研究Java网络爬虫时总体过了一遍Jsoup的相关知识,因此对部分知识点进行了总结梳理。 在使用Jsoup下载图片、PDF和压缩文件等文件时,需要将响应转化...
前段时间,有小伙伴多次在后台留言询问的问题。经过这两个多月以来的收集与整理,汇集了,包括。爬虫作为机器学习语料库构建的主要方式,...我为此花费了数月时间,经常做到深夜,把自己的学习笔记整理成了这份教程。
'''模拟登录京东'''print('\[INFO\]: 检测到已有会话文件session.pkl, 将直接导入该文件...')else:f.close()接着去京东抓一波包,一样的套路,有种屡试不爽的感觉:看看请求这个接口需要提交的参数:area: 不用管,...

而想成功的请求成功互联网上的开放/公开接口,必须知道它的URL、Headers、Params、Body等数据是如何生成的。 JavaScript逆向工程是指通过分析JavaScript代码和运行行为来理解程序的内部机制。这种技术可以用于破解...
从数据爬虫实战角度出发,让你在数据科学领域迈出重要的一步,开启Data Science职业之旅! 2.【课程特点】 课程精选多个实战项目,从易到难,层层深入。 不同项目解决不同的抓取问题,带你从容抓取主流网站,让你...
推荐文章
- Java面向对象程序设计 第七章总结_方法的返回值被错误地处理为一个非空的对象-程序员宅基地
- RFX2401C skyworks射频2.4GHZ ZIGBEE/ISM发射/接收RFeIC_rfx2401c csdn-程序员宅基地
- Lambda简便方法引用、构造方法引用_lambdautils.getname-程序员宅基地
- sql表格模型获取记录内容_SQL Server和BI –如何使用Excel记录表格模型-程序员宅基地
- GateWay配置_grateway配置-程序员宅基地
- 云栖专辑| 阿里毕玄:程序员的成长路线-程序员宅基地
- Android 导出traces.txt 遇到的坑_biotraces无法导出-程序员宅基地
- 【ffmpeg 给视频添加背景音乐,去掉视频背景音乐原声】_ffmpeg.net 视频 加入 音频-程序员宅基地
- cocos2d-x3.2 lua 返回键监听_cocos2dx-lua cc.director:getinstance():endtolua()-程序员宅基地
- etcc oracle ebs,Oracle EBS12.2.6 克隆问题集合-程序员宅基地